Mysterious rise in 404 errors in GWT
Google Webmaster Tools is reporting that in the last month the number of 404 errors has skyrocketed from about 9,000 to 77,000.
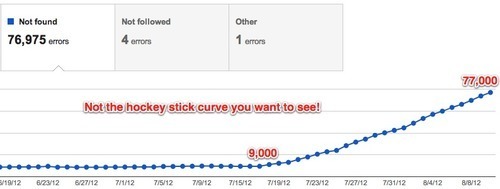
We can’t figure out why. In fact, when we check our server logs and look for 404 status codes returned to Googlebot in the last month, there’s only about 10,000 (which might even have some duplicate records..we haven’t checked).
So what in the name of Tim Berners Lee is going on?
Let’s look at the types of URLs Google Webmaster Tools (GWT) is reporting:
- URLs from this requests page. These are requests people have made and this page hand hundreds of requests listed. So that makes sense. These are non-existent pages (the comparisons haven’t been created yet!) so they return 404s. And Google found the 404s so all that make sense.
- Hundreds of non-existent URLs that were never on the site. Like /Intel_EP80579_with_Intel_QuickAssist_Technology,_1200_MHz (the correct URL is /difference/Special:Information/Intel_EP80579_with_Intel_QuickAssist_Technology,_1200_MHz). Google doesn’t say where it found them. Generally GWT tells you whether the URL was found in a sitemap or is linked from somewhere. But for the URLs it’s reporting to us, no such info is available.
Here’s the deal, though. All the processors and all the user requests don’t add up to more than 2,500 URLs. So where the hell is Google getting 77,000 of them?
What we did
- Added <meta name=“robots” content=“nofollow” /> to the comparison requests page so all the non-existent user requests aren’t crawled. This is something we should have done a long time ago. Also stopped listing the hundreds of non-existent URLs on this page. Now we only show the most recent user requests. The nagging feeling we get, however, is whether the nofollow tag will prevent Google from de-indexing all the old 404 URLs that were listed on this page. Will Googlebot notice that these URLs have now been removed from the page or will it see the nofollow tag and start ignoring the page from a crawling and link finding perspective? We don’t know.
- We now return 410 for most of the non-existent URLs that Google is reporting. We found a pattern for the 404s that Google is reporting and the ones we uncovered in our server logs. And with some nginx config settings we can now return 410 because Google apparently removes 410s faster than 404s.
Google Webaster Tools: The Good, the Bad and the Ugly
The Good: They tell you there’s something wrong with your site! +1 for transparency and proactive information sharing. They even give you a list of URLs they found, as well as where to fix the problem (sitemap or list of pages that link to the bad URL). All of this information is very helpful and kudos to them for providing it.
The Bad: They only tell you about 1,000 URLs and don’t give you the full list. The CSV download is missing crucial info viz. where the URL is being linked from. Where did Google find the URL?
The Ugly: The rise reported by GWT does not reconcile with the number of 404s returned to Googlebot as indicated by our server logs. And there’s no way to know when Google will remove these 404s from its index.
Why could this be happening?
We honestly have no idea. There are only guesses. Right now we’re leaning towards a theory that blames spam. Spammers sometimes create user accounts on Diffen (which is a wiki and runs on the awesome MediaWiki platform - the same software that powers Wikipedia). Mediawiki has user pages where registered users can write a little about themselves. We require reCAPTCHA when users sign up but spammers manage to defeat it from time to time. They have been posting spam by creating such user pages. It’s possible they are linking to thousands of such user pages but only succeeding in actually creating a few of them, (which we find and delete). It could even be negative SEO by a third party but that’s not our favorite theory right now.
1 Notes/ Hide
 e-assistant-blog liked this
e-assistant-blog liked this  thediffenblog posted this
thediffenblog posted this