Redis based triple database
Meshin application relies on back-end triple store for holding person semantic index and for processing front-end queries. This back-end store is built on top of open source in-memory key-value database Redis. Before getting into details of how triples are represented and queried I will briefly introduce essential Redis features. Fill free to skip following paragraph if you are familiar with Redis.
Redis is key-value store where keys are binary strings and values can be either simple binary strings or higher order data structures. These data structures include ordered lists, unordered unique sets, secondary level hash tables (hsets) and weight sorted sets (zsets). Redis exposes its functionality through simple text based protocol. Protocol defines number of commands and corresponding replies. Commands are either general for all kinds of key-values or specialized for value type. For example SET A X associates binary string value X with key A.

RPUSH A X appends value X to the end of list at key A.

SADD A X inserts value X into unordered set at key A.
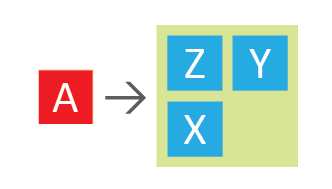
HSET A P X inserts field P with value X into hset at key A.
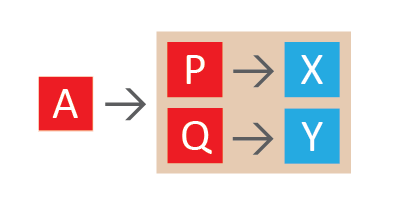
There are several commands that allow to combine values in interesting ways. For sets it is possible to union, intersect or subtract sets and store the resulting set with new key. Corresponding commands are SUNIONSTORE, SINTERSTORE, SDIFFSTORE. Even more interesting is “for each” operation with patterns expanded with each element of input set or list. When expanded star (*) character is replaced with each value from input. Pattern can be just “key” for binary strings lookup or “key->field” for hsets field lookup. For example if pattern is A* and input set is A, B, C command will produce output from string values of AA, AB, AC keys. Now if pattern is *->P and input set it A, B, C command will produce output from values of A->P, B->P, C->P hset fields. In addition “for each” operation allows sorting and paging of the result by yet another specified pattern, therefore the name of command is SORT. SORT command also allows to store resulting list with new key.
Combination of SUNIONSTORE, SINTERSTORE, SDIFFSTORE, SORT and similar commands allows for interesting use case. Sufficiently complex query can be expressed as dataflow between inputs, intermediate results stored as temporary keys and output result returning optionally sorted and paged values. Ability to store intermediate result in temporary key is essential for performance – it allows to avoid roundtripping of intermediate results between Redis database and application server. In addition Redis enables pipelined execution where multiple commands are sent without waiting for replies. This creates condition for “stored procedure”-like execution with single roundtrip to database. Experimentally Redis supports embedded Lua scripting where instead of pipelining multiple do-and-store commands it is possible to submit single EVAL command with equivalent Lua script.
Now let’s illustrate such dataflow approach with specific query and triples between person, address, participant and message objects from previous post. Let’s say we want to retrieve ids for twitter messages exchanged with specific person ids: P0, P1, P2. Messages need to be sorted by their timestamp in descending order and paged to top 20. Before jumping into query details we first need to understand how triples are represented in Redis. For example we have the following object -> predicate -> subject triples that assumes uniqueness of predicate per object.
A0 -> person-of-address -> P0
A1 -> person-of-address -> P0
A2 -> person-of-address -> P1
This means that person P0 has two addresses A0 and A1 and person P1 has one address A2. In Redis we place the following hset keys to represent object to subject reference.

And following set keys to represent reverse subject to object reference.

Now let’s look at query dataflow.

- First we initiate temporary set T0 with P0, P1, P2 in it.
- Next we need to get set of corresponding address ids. To do this for each set pattern “*:person-of-address” we union and store in T1. If person object P0 has two address objects with ids A0 and A1 pointing to it there will be reverse reference set P1:person-of-address containing A0 and A1. Now T1 contains union of corresponding address ids.
- Next we need to filter and leave only address ids of “twitter-address” class. To do this we intersect “twitter-address:class” set with T1 and store in T2. “twitter-address:class” set is similar reverse reference set for all twitter class ids.
- Next we need to get set of corresponding participant ids. Again to do this for each set pattern “*:address-of-participant” we union and store in T3. Keeping in mind that “A0:address-of-participant” would contain all participant ids pointing to address A0.
- Next we need to get corresponding message ids. This is done for each hset pattern “*->message-of-participant” we lookup field value and store into T4.
- Finally we sort T4 by hset pattern “*->date-time”.
- Returned result contains pairs of message id and subject.
Note that SFOREACHUNIONSTORE command does not exist in Redis. Originally you would have to resort to forking Redis and coding new command or do it in application server code, which would hurt performance. Using Lua scripting extension of Redis it is very easy to implement SFOREACHUNIONSTORE with EVAL command and following Lua script.
local p = string.find(ARGV[1], '*')
local pre = string.sub(ARGV[1], 1, p - 1)
local post = string.sub(ARGV[1], p + 1, -1)
local x = redis.call('SMEMBERS', KEYS[2])
for i = 1, #x do
local y = redis.call('SMEMBERS', pre .. x[i] .. post)
for j = 1, #y do
redis.call('SADD', KEYS[1], y[j])
end
end
return redis.call('SCARD', KEYS[1])
I mentioned before that Meshin index for each user is sharded. Users are required to authenticated in order to access their data. This enables minimizing shared resources and provides with good scalability path. Architecture with large cluster of commodity computers each running multiple instances of Redis becomes possible. In our initial deployment we operate cluster with 1TB of RAM. We expect it to scale up to 30TB with current commodity hardware. In my next post I will describe this architecture in details.
54 Notes/ Hide
crazymazafaka liked this
michel-slm liked this
jinksunk liked this
 hdd-data-recovery-blog reblogged this from petrohi
hdd-data-recovery-blog reblogged this from petrohi - hdd-data-recovery-blog liked this
heatheryi982-blog liked this
petrohi posted this
- Show more notes